AI knowledge distillation: The key to DeepSeek’s refinement?
Paris Tung, Associate (London)

We highlight the findings and implications of a paper that outlines the launch of DeepSeek’s R1 model, which shook the AI industry in January 2025.
LITERATURE
We review a paper entitled ‘DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning’, written by DeepSeek AI on its GitHub and archived on arXiv on 22nd January 2025. The paper has made a splash among data users who cover relevant tech stocks, build AI models or procure sentiment data.
QUICK VIEW
- DeepSeek demonstrated a new AI development pipeline which results in a high-performance model on par with Open-AI’s, at a lower cost.
- The pipeline combines multiple affordable training steps, particularly using knowledge distillation from other powerful models like Alibaba’s Qwen2.5 and Meta’s LLaMA3. This brought the concept of knowledge distillation in machine learning to the eyes of public.
- While this method of model enhancement, including knowledge distillation, can be economical and effective when trained with a more powerful base model, large-scale machine-learning training resources are still required.
- The results are provided as open-source models, including R1-Zero, R1 and six other distilled models of varying sizes (1.5B to 70B parameters1).
- DeepSeek aims to advance beyond the current legal boundaries of artificial intelligence.
MODELS AND KEY METHODOLOGY
R1-Zero model: The first attempt
- DeepSeek’s team aimed to create a better model that surpassed its previous model, V3. The result of these efforts became known as the R1-Zero model.
- R1-Zero is trained purely through rule-based reinforcement learning (RL)2 training, which enhances its reasoning ability, reducing the need for substantial supervised fine-tuning (SFT)3. As such, the model can be trained through self-correction, cutting the human resources needed to prepare and review a high-quality taxonomy, and fine-tune the weight for specialisation to balance potential abnormal distribution from training data.
- DeepSeek claims that past training methods primarily relied on SFT, but struggled to achieve general reasoning performance comparable to OpenAI's models, because most vendors usually don’t have that amount of human and data resources. In contrast, R1-Zero excelled in reasoning. However, it has poor readability and is weak at tackling multiple languages because it focuses on mathematical reasoning.
R1 model: The current product
R1 is the latest model created by fixing R1-Zero’s readability issues (as of February 2025). To maintain the reasoning ability displayed by R1-Zero, this R1 model also draws on other techniques DeepSeek has developed, as well as more powerful models. The pipeline can be roughly divided into four stages:
- RL phase 1: DeepSeek AI uses thousands of data points to solve cold-start issues, which occur when a brand-new system has little or no data to make accurate predictions or recommendations. Next, it provides a small number of step-by-step reasoning examples (i.e. Chain-of-Thought) collected from LeetCode, a question bank often used by programmers to practice coding skills, to train models to fine-tune DeepSeek’s V3. This is used as a starting point for RL, and applies the same large-scale RL training process as in R1-Zero.
- SFT phase: After reaching convergence in RL, DeepSeek took samples from the results to generate fine-tuned SFT data. Next, DeepSeek mixes the aforementioned SFT data with data that has diverse domains used by its previous V3 model, e.g. writing, factual QA and self-cognition, so as to retain the latter as a base model to enhance overall capabilities.
- RL phase 2: To this point, the model has various underlying processing pipelines running. For reasoning, the model uses rule-based reward signals to guide the learning process, which was developed in R1-Zero. For general text data, DeepSeek prioritises the pipeline that its previous base models (e.g. V2 and V3) adopted. To minimise the interference between different underlying reasoning processes, DeepSeek conducted another RL to enable the model to handle all types of scenarios while being specialised in different domains. As a result, both the model's reasoning ability and readability are enhanced.
- Distillation phase: Finally, DeepSeek uses SFT without another RL to fine-tune dense models, using various versions of Alibaba’s Qwen and Meta’s LLaMA as the base model to distil4 R1 into smaller models.KEY FINDINGS
R1 passed a benchmark test with a score of 78.8% on its first try of an American high school-level math exam (AIME 2024). It also scored 97.3% on its first try of an industry-standard 500 math test designed to test advanced problem-solving skills (MATH-500 pass@1). Both scores surpassed that of OpenAI-o1-1217, showing competitive performance on logic-intensive and long-context reasoning tasks.
Benchmark performance of DeepSeek-R1
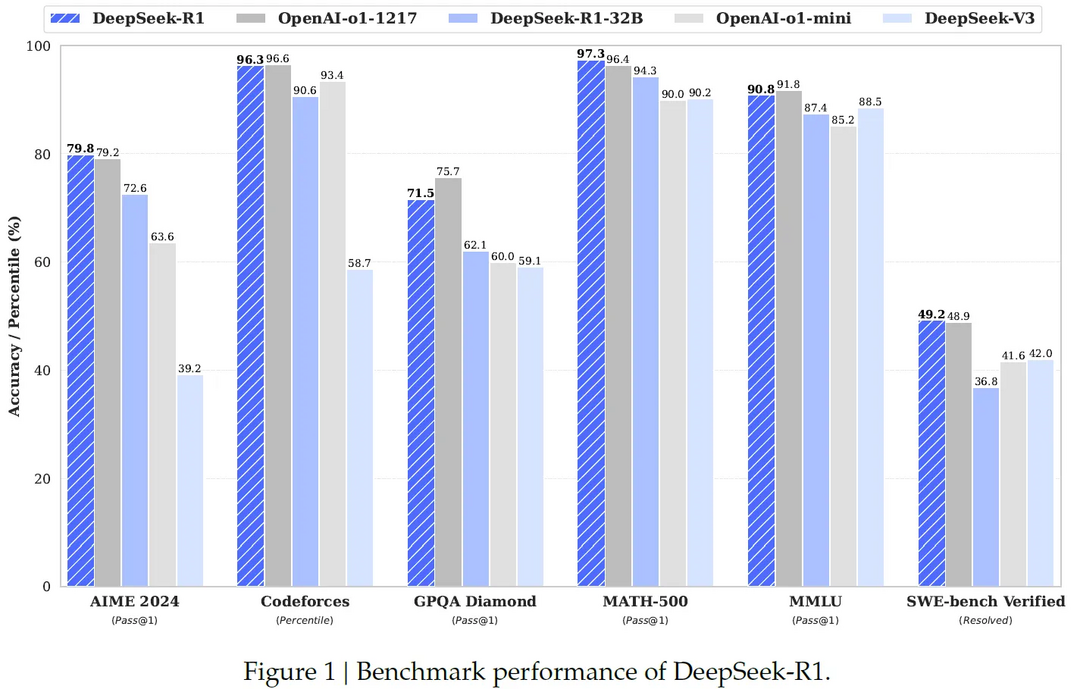
Source: DeepSeek
The benchmark scores of distilled models can also surpass the original model or other mainstream models when they reach a certain parameter size. For example, DeepSeek-R1-Distill-Qwen-7B achieves 55.5% on AIME 2024 pass@1, surpassing 50% of QwQ-32B-Preview.
Comparison of R1 distilled models and other comparable models against reasoning benchmarks
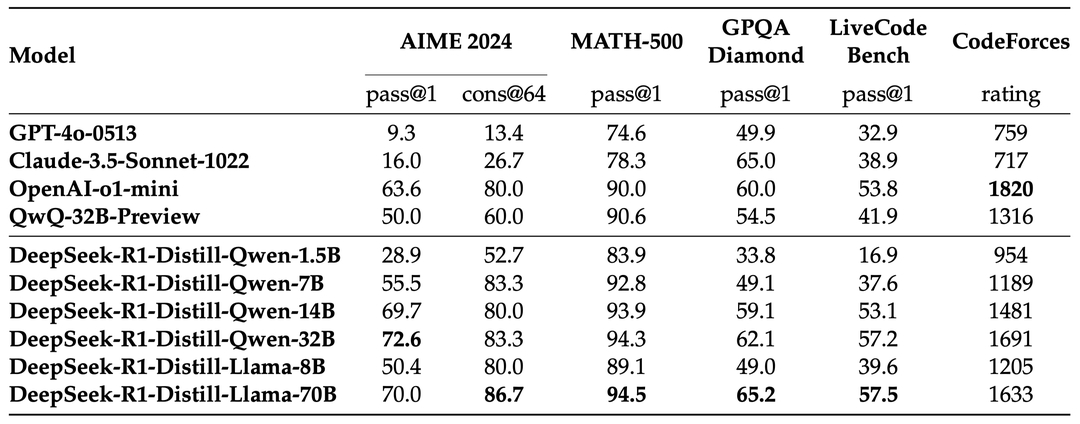
Source: DeepSeek
IMPLICATIONS
DeepSeek’s paper proves the following:
- Through its R1-Zero methodology, DeepSeek shows that reasoning capabilities can be enhanced purely through RL, effectively reducing reliance on extensive supervised datasets.
- A model can be powerful in reasoning and readability by incorporating fine-tuned SFT data from the results of RL training, and domain-specific training based on other large models like V3 and multiple RL training to minimise the interference between underlying models that have different specialities.
- Knowledge distillation is economical as it requires minimal computational resources compared to models trained from scratch and is effective as distilled models can surpass the original models on multiple reasoning benchmarks.
Knowledge distillation has been a common practice for machine learning since 2015 and has since expanded to various industries. We foresaw that more vendors would adopt the approach for LLMs, as Alpaca did:
“The price competition intensified when Stanford announced Alpaca, a model based on Meta's LLaMA 7B. Alpaca allows low-spec computers like Raspberry Pi to run models that replicate the power of GPT-3 for just a few dollars. Data vendors could consider taking a similar approach to mimic GPT-level NLP to improve their data processing abilities.” (ChatGPT: alternative data use cases and implications, March 2023).
Indeed, most vendors’ ‘proprietary’ models we have encountered are based on LLaMA (or a mix of open-source models) and are fine-tuned with resources such as proprietary financial taxonomy.
DeepSeek’s R1 represents a significant advancement in model architecture due to its innovative pipeline implementation. The model demonstrates enhanced reasoning capabilities and balanced general performance metrics. While the framework still needs large-scale reinforcement learning, it achieves greater cost-effectiveness by streamlining several computational steps that previously required extensive supervised training datasets or resources. The architecture leverages existing powerful models as its foundation, incorporating proprietary techniques developed by DeepSeek’s V2 and V3 models. The result is the latest model's impressive benchmark scores and, ultimately, the app's release.
UNADDRESSED CONCERNS
Despite the impressive performance, uncertainties remain:
- Distilled models have been limited to academic research or used only to provide outputs, rather than presented as a standalone model, which could be against open-source providers' licence policies. Potential legal issues could be raised if R1 does not simply 'distil' from its proprietary and open-source models. This resonates with the backlash from OpenAI which accuses DeepSeek of conducting large-scale API access multiple times in the past year.
- Despite DeepSeek's claims of affordability, its approach still requires substantial computing power, even if not as much as required by the major players. Given US restrictions on Nvidia's advanced chips, questions remain about their hardware setup. The company has not disclosed which chips trained and powered R1, with speculation ranging from modified H800s (as used in V3), restricted H100s or Huawei's 910C chips.
FINAL THOUGHTS
We believe an important question for alternative data users will be: can we track potential market disruption from tech events like this? How do we evaluate the ensuing impacts? We believe data that monitors R&D communities; tracks app downloads and usage; analyses social media and news sentiments; and signals geopolitical and cybersecurity events could gain traction or be useful for global data buyers trying to answer those questions.
Please see the details of highlighted datasets in our complement Intelligence report “Can we predict AI market shifts? Learning from DeepSeek”.
Footnotes
1. Parameters: Numerical values that define the model's size and complexity, measured in billions.
2. Reinforcement Learning (RL): A training method using a reward system to enhance model capabilities autonomously.
3. Supervised fine-tuning (SFT): A training process that requires labelled training data to improve model performance.
4. Knowledge distillation: A technique where knowledge from a larger, more powerful model is transferred to create smaller, more efficient models.